Message Queues & Kafka : An Overview
Overview in layman's term:
We have a monolithic application let's suppose. The server calls are handled by endpoints and things are going smooth. With time , the number of request grow. Now we want to scale up. We try to add more server nodes , where each node can now handle number of requests in parallel. The server nodes can be distributed. We still get latency. To improve upon that , we try to scale up further by breaking the services deployed on server with microservices . These microservices may reside on different nodes . This now becomes a distributed system. Within a distributed system , the major challenge is to communicate between nodes . We could use plain https , but then within a large systems , it would be very difficult to maintain data flow and offsets at the receiving end. This bottleneck is resolved by use of message queues, where the producer puts through messages into a queue and consumer consumes those messages from the queue. This way , data loss and latency are minimised. Also , this helps in making server calls asynchronous.
Consider another example :
Have you ever done a travel booking through a OTA website ( e.g: Expedia) . When you have completed a booking , you get a message on the final screen mentioning that the booking details shall be mailed to you separately . Now consider the booking flow. It essentially involves search , select, pax details, payment , confirmation and 'mail eticket' , in that order.Imagine for a very popular website like Expedia , thousands of request would be going to 'mail eticket' service per second. For this service to be highly available , calls need to be asynchronous. The client need not wait for mail to be sent immediately to the user , to show the confirmation page. Here comes the role of enqueuing events for such service. For each confirmed eticket , the booking service may enqueue an event for 'mailEticket' service. The mailEticket service can keep picking up events from the queue and process them . To scale up, several nodes can enqueue the queue and several nodes can dequeue it. For fault tolerance, an offset can be maintained along with the message in the queue.
Message Queues - Definition :
A message queue is nothing but an asynchronous mechanism to enqueue communication messages from the producing end , and these can be consumed by the receiving end . There can be multiple producers who produce messages of different kind and the consumer can subscribe to one or more kind of messages in order to receive them . |
| Image credit [AWS] |
Types Of Messaging Systems :
There are various available open source/licensed software that provide a complete messaging solution for distributed systems. JMS, Apache ActiveMQ, RabbitMQ, Reddis, Kafka , Amazon SQS etc. Most of the MQ series work upon the message queueing system , while some like Kafka work on the publish subscribe model .
Queue Model :
Also known as 'Point-to-Point Messaging system' . Here a message can be consumed by a single consumer only. Once the message is consumed, the message is lost. The advantage of point to point model is that it allows to scale processing by adding multiple consumer instances.Pub - Sub Model:
Publish - Subscribe model is a pattern similar to 'Observer' pattern, the only difference being the publisher and subscriber are not aware of each other and the message communication happens through a broker. A publisher is a piece of code that adds message to a queue or a topic. A subscriber is a piece of code that listens to messages published through one or more topic. i.e, a subscriber subscribes to a topic.
 |
| Image credit [Microsoft] |
Kafka Overview :
Kafka is primarily a streaming platform and a messaging system. It can also be used as a storage system for streams of records. It works upon the publish subscribe model and is arguably highly scalable, durable and fault tolerant .
Kafka runs as a cluster deployed on one or more server nodes. It stores messages in streams of records into categories called as topics.
Kafka runs as a cluster deployed on one or more server nodes. It stores messages in streams of records into categories called as topics.
 |
| Image Credit [Apache Kafka] |
Kafka API's :
Kafka has following API's
- Producer API: publishes a stream of records to the Kafka topics.
- Consumer API: allows subscription to one or more topics and processing of stream records under topics
- Streams API: allows for stream processing . This api allows processing of an input stream from an input topic and producing an output stream to the output topic
- Connector API: facilitates building and reusing producers and consumers that connect Kafka topics to data systems or applications in the distributed system
- AdminClient API: The AdminClient API supports managing and inspecting topics, brokers, acls, and other Kafka objects.
- Legacy API: apart from these , many Legacy API are included in Kafka, some of which are in Scala
Topics
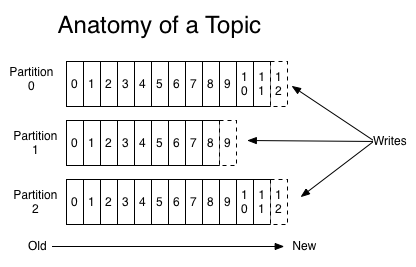
A topic is a category name to which the records are published by producer. Each Kafka topic is multi-subscriber, which means it can have more than one consumer subscribing to messages published to it.
Each topic consists of multiple partitions contained in a partition log where in a partition consists of records with sequential ids. Each topic consists of multiple partitions contained in a partition log where in a partition consists of records with sequential ids. Kafka maintains the records for a configurable amount of time , regardless of how many times a message record has been consumed by one or more consumers.
A Consumer maintains an offset for each partition log, in order to know at what position a consumer is for that partition log. A consumer can either advance the offset sequentially or move to an older record for re-processing it need be.

Partitioning of topic records allows for better scaling and parallel processing. Each partition . Partitions are distributed on servers on Kafka cluster , such as there is a leader and one or more follower server nodes for each partition , with partition data replicated across them for fault tolerance.
Kafka Cluster : Broker & Zookeeper

Zookeeper is a highly fault tolerant configuration management system , which does configuration mapping, broker management , consumer offset management etc . In a way, Kafka heavily relies on Zookeeper.
Producer, Consumer & Consumer Group :
Producers publish data(message) to the topic of their choice.
Consumers subscribe to one or more topics. Consumers are labelled under 'Consumer Groups' where a consumer group can subscribe to a to one or more topics. Records are pushed to consumer instances within one or more consumer groups.
Consumers subscribe to one or more topics. Consumers are labelled under 'Consumer Groups' where a consumer group can subscribe to a to one or more topics. Records are pushed to consumer instances within one or more consumer groups.
 |
| Image Source [Apache Kafka] |
Why Kafka ?
Kafka provides for many advantages over other available MQs :
- Kafka shares advantages of both Queue Model ( High processing throughput scaling) and Pub-Sub model( multiple subscription by consumer)
- Fault Tolerance ( Records replicated across multiple servers)
- Better Ordering guarantee ( via partitioning)
- Highly Available ( Multiple brokers , managed by heavily reliable Zookeeper)
- Highly scalable and high performance storage
- Streams API : provides for efficient stream data processing.
========================================================================
References :
https://kafka.apache.org/documentation/IBM Knowledge Center
docs.microsoft.com

Comments
Post a Comment